
こんにちは、管理人のアカツキです。Pythonによる火山カメラ画像のキャプチャプログラムの解説もいよいよ最後のブロックです。前回までの記事をまとめておきます。

(再掲)火山カメラ・キャプチャ コード
例によりまして、全体のコードを再掲します。
"""
JMA火山監視カメラキャプチャ Ver.1.01
・JMAの火山監視カメラ画像をキャプチャする
・連続キャプチャを実施する(重複はスキップ)
・火山名をリストから選択する
・最初のリストはよくアクセスすると思われる火山
・火山リストをアップデート(20220727更新分)
"""
# ブロック1
from selenium import webdriver
from selenium.webdriver.chrome import service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import os
import requests
import time
# ブロック2
dir_path = "(適当なディレクトリ)/volcano_camera/"
fav_volcano = {1:'十勝岳 白金模範牧場',
2:'阿蘇山 草千里',
3:'桜島 牛根',
4:'諏訪之瀬島 寄木',
5:'その他'}
area_volcano = {1:'北海道',
2:'東北地方',
3:'関東・中部地方',
4:'伊豆・小笠原諸島',
5:'九州地方',
6:'戻る'}
hokkaido_volcano = {1: 'アトサヌプリ 北東山麓', 2: 'アトサヌプリ 硫黄山駐車場北',
3: 'アトサヌプリ 屈斜路湖南', 4: '雌阿寒岳 上徹別',
5: '雌阿寒岳 阿寒富士北', 6: '大雪山 忠別湖東',
7: '大雪山 旭岳姿見2', 8: '十勝岳 白金模範牧場',
9: '十勝岳 避難小屋南東', 10: '樽前山 別々川',
11: '倶多楽 414m山', 12: '倶多楽 地獄谷',
13: '有珠山 東湖畔', 14: '有珠山 月浦',
15: '北海道駒ヶ岳 鹿部公園南東', 16: '北海道駒ヶ岳 赤井川',
17: '北海道駒ヶ岳 剣ヶ峯', 18: '恵山 高岱',
19: '恵山 火口原', 20: '戻る'}
tohoku_volcano = {1: '岩木山 百沢東', 2: '八甲田山 大川原', 3: '八甲田山 地獄沼',
4: '十和田 銀山', 5: '秋田焼山 栂森', 6: '岩手山 柏台',
7: '岩手山 黒倉山', 8: '鳥海山 上郷2', 9: '栗駒山 大柳',
10: '栗駒山 展望岩頭', 11: '蔵王山 遠刈田温泉', 12: '蔵王山 上山金谷',
13: '蔵王山 刈田岳', 14: '蔵王山 御釜北', 15: '吾妻山 上野寺',
16: '安達太良山 若宮', 17: '安達太良山 鉄山', 18: '磐梯山 剣ケ峯',
19: '磐梯山 櫛ヶ峰', 20: '戻る'}
kanto_tyubu_volcano = {1: '那須岳 湯本ツムジケ平', 2: '那須岳 日の出平北', 3: '日光白根山 歌ヶ浜',
4: '日光白根山 上小川', 5: '草津白根山 奥山田', 6: '草津白根山 逢ノ峰山頂',
7: '草津白根山 草津', 8: '浅間山 鬼押', 9: '浅間山 追分',
10: '新潟焼山 宇棚', 11: '弥陀ヶ原 芦峅', 12: '焼岳 中尾峠',
13: '乗鞍岳 乗鞍高原', 14: '御嶽山 三岳黒沢', 15: '御嶽山 奥の院',
16: '白山 白峰', 17: '富士山 萩原', 18: '箱根山 宮城野',
19: '箱根山 大涌谷', 20: '箱根山 箱根峠', 21: '伊豆東部火山群 大原',
22: '伊豆東部火山群 大崎', 23: '戻る'}
izu_ogasawara_volcano = {1: '伊豆大島 北西外輪', 2: '伊豆大島 中央火孔北', 3: '新島 式根',
4: '神津島 前浜南東', 5: '三宅島 坪田', 6: '三宅島 神着',
7: '三宅島 山頂火口北西', 8: '八丈島 楊梅ヶ原', 9: '青ヶ島 手取山',
10: '戻る'}
kyusyu_volcano = {1: '鶴見岳・伽藍岳 塚原無田', 2: '九重山 上野', 3: '九重山 星生山北尾根',
4: '九重山 飯田大原', 5: '阿蘇山 草千里', 6: '阿蘇山 車帰',
7: '阿蘇山 南阿蘇村', 8: '雲仙岳 野岳', 9: '雲仙岳 垂木台地南',
10: '霧島山 猪子石(新燃岳)', 11: '霧島山 猪子石(御鉢)', 12: '霧島山 御鉢火口南縁',
13: '霧島山 高原西麓', 14: '霧島山 八久保', 15: '霧島山 韓国岳',
16: '霧島山 えびの高原', 17: '霧島山 硫黄山南', 18: '桜島 牛根',
19: '桜島 東郡元', 20: '桜島 垂水荒崎', 21: '桜島 中央港新町',
22: '薩摩硫黄島 岩ノ上', 23: '口永良部島 本村西', 24: '口永良部島 屋久島吉田',
25: '諏訪之瀬島 寄木', 26: '諏訪之瀬島 キャンプ場', 27:'戻る'}
area_volcano2 = {'北海道':hokkaido_volcano,
'東北地方':tohoku_volcano,
'関東・中部地方':kanto_tyubu_volcano,
'伊豆・小笠原諸島':izu_ogasawara_volcano,
'九州地方':kyusyu_volcano}
# ブロック3
# メニューを行き来するためのフラグを設定
Flag = True
while Flag:
for vkey1, vvalue1 in fav_volcano.items():
print(f"{vkey1} : {vvalue1}")
select_vkey1 = input("火山を選択してください [No.?] >>> ")
select_vkey1 = int(select_vkey1)
select_vvalue1 = fav_volcano[select_vkey1]
# 1~6を選んだ場合の処理→値を取得してループ離脱
if not select_vvalue1 == "その他":
select_volcano = select_vvalue1
break
elif select_vvalue1 == "その他":
# もう一つwhileを入れる
while Flag:
for vkey2, vvalue2 in area_volcano.items():
print(f"{vkey2} : {vvalue2}")
select_vkey2 = input("地域を選択してください [No.?] >>> ")
select_vkey2 = int(select_vkey2)
select_vvalue2 = area_volcano[select_vkey2]
if select_vvalue2 == "戻る":
# 再度前の画面に戻る
break
elif select_vvalue2 != "戻る":
for vkey3,vvalue3 in area_volcano2[select_vvalue2].items():
print(f"{vkey3} : {vvalue3}")
select_vkey3 = input("火山を選択してください [No.?] >>> ")
select_vkey3 = int(select_vkey3)
select_vvalue3 = area_volcano2[select_vvalue2][select_vkey3]
if not select_vvalue3 == "戻る":
# 火山名を取得してループを抜ける
select_volcano = select_vvalue3
Flag = False
elif select_vvalue3 == "戻る":
# 地域選択画面に戻る
pass
print(select_volcano,"を選びました")
print(select_volcano,"にアクセスします")
# ブロック4
chrome_driver = "(適当なディレクトリ)/chromedriver.exe"
chrome_service = service.Service(executable_path=chrome_driver)
driver = webdriver.Chrome(service=chrome_service)
wait = WebDriverWait(driver=driver, timeout=10)
driver.implicitly_wait(5)
driver.set_window_position(50,50)
driver.set_window_size(1400,1300)
# JMAの監視カメラ画像のページに直接アクセスする
driver.get("https://www.data.jma.go.jp/vois/data/tokyo/volcam/volcam.php")
# wait.until(EC.presence_of_all_elements_located)
# 選択された火山カメラを開く
volcam = driver.find_element(By.LINK_TEXT,select_volcano)
volcam.click()
# wait.until(EC.presence_of_all_elements_located)
# スライダを左端に移動
driver.find_element(By.CSS_SELECTOR,"img[src='./icon/player/oldest.png']").click()
# 早送りボタンを取得
forward = driver.find_element(By.CSS_SELECTOR,"img[src='./icon/player/next-frame.png']")
# ブロック5
# 画像を保存する(繰り返し)
# 撮影枚数を取得
img_num = driver.find_element(By.XPATH,"//*[@id='main']/form/table[2]/tbody/tr[2]/td/table/tbody/tr[3]/td[5]/input[3]")
img_num = img_num.get_attribute("value")
time.sleep(1)
for i in range(int(img_num)):
img_tag = driver.find_element(By.NAME,"myImg")
img_url = img_tag.get_attribute("src")
img = requests.get(img_url)
file_name = os.path.basename(img_url)
# 保存ディレクトリの作成
# 取得した火山名を使う
save_dir = os.path.join(dir_path,select_volcano)
# if not文で判断→フォルダがない→False→if notはTrue→フォルダを作る
if not os.path.isdir(save_dir):
os.makedirs(save_dir)
# 撮影の重複をチェック
check_file = os.path.join(save_dir,file_name)
# if notで判定する
# 条件が真ならif notは偽を返す
# 条件が偽ならif notは真を返す
# ファイルがない=撮影していない=if notがTrue=Trueの処理=キャプチャする
if not os.path.isfile(check_file):
with open(check_file,"wb") as f:
f.write(img.content)
# 次の時間に移動
forward.click()
time.sleep(1)
driver.quit()
print("終わりました")プログラムの機能は次のようになっています。
JMA火山監視カメラキャプチャ Ver.1.01(volcano_capture.py)
- 気象庁(JMA)が提供している火山監視カメラ画像について、
任意の火山画像をキャプチャ(保存)する - キャプチャする火山名はリストから選択する(番号を入力して指定)
- 画像を保存するフォルダ・ファイル名は自動で生成する
- 火山リストを更新(2022.7.27 カメラ追加のプレスリリースあり)
全体コードにはその役割ごとにブロック番号を付けています。
ブロック一覧とその役割
- プログラムで使用するモジュールの呼び出し
- ファイル保存や火山名の選択に使う変数やデータ
- 火山選択メニュー
- 選択された火山カメラをブラウザで読み込む
- キャプチャした画像の保存処理
今回はブロック5についての解説です。
ブロック5・キャプチャ画像の保存処理
# ブロック5
# 画像を保存する(繰り返し)
# 撮影枚数を取得
img_num = driver.find_element(By.XPATH,"//*[@id='main']/form/table[2]/tbody/tr[2]/td/table/tbody/tr[3]/td[5]/input[3]")
img_num = img_num.get_attribute("value")
time.sleep(1)
for i in range(int(img_num)):
img_tag = driver.find_element(By.NAME,"myImg")
img_url = img_tag.get_attribute("src")
img = requests.get(img_url)
file_name = os.path.basename(img_url)
# 保存ディレクトリの作成
# 取得した火山名を使う
save_dir = os.path.join(dir_path,select_volcano)
# if not文で判断→フォルダがない→False→if notはTrue→フォルダを作る
if not os.path.isdir(save_dir):
os.makedirs(save_dir)
# 撮影の重複をチェック
check_file = os.path.join(save_dir,file_name)
# if notで判定する
# 条件が真ならif notは偽を返す
# 条件が偽ならif notは真を返す
# ファイルがない=撮影していない=if notがTrue=Trueの処理=キャプチャする
if not os.path.isfile(check_file):
with open(check_file,"wb") as f:
f.write(img.content)
# 次の時間に移動
forward.click()
time.sleep(1)
driver.quit()
print("終わりました")キャプチャの作業手順は?
まずキャプチャの手順を一度確認しておきましょう。前回の記事においてこのようなレシピを掲載していました(少し編集しています)。
火山カメラ画像キャプチャの手順
- 画像を最も古い撮影日時に切り替える
- 撮影枚数が1の状態にする
- キャプチャを実行
- 画像を一つ先のものに切り替える
- 2.に戻る
このうち、手順1と手順3の準備が完了したのでしたね。残すは二つ。手順2のキャプチャと手順4の2.に戻るです。手順2のキャプチャにおいては、直接画像URLにアクセスしてダウンロード保存する方法を選択しました。
ちなみに蛇足だとは思いますが、キャプチャとは一般的にデジタル界隈においてディスプレイに映っている対象物をスクリーンショットなどで切り取り、あるいはコピーをして画像として保存することを指すかと思います。それを本件に当てはめるならば、火山画像をスクリーンショットして保存、または画像を右クリックしてコンテキストメニューを表示させ、そこから画像を保存する操作が第一にイメージされることかと思います。
しかし本プログラムではそのようなことをせず、直接URLにアクセスして保存を行っています。なので前段の内容が(一般的な意味での)キャプチャであると捉え、プログラムの機能説明に広義の、という意味合いを込めてキャプチャ(保存)と記しています。細かいだろうと思われるかも知れませんが念のため記しておきます。
さて本題ですが、キャプチャの肝は直接URLを取得することですので、後はそれを何枚撮るのか?ということになります。それが決まれば一連の作業を所定回数繰り返すことでキャプチャ完了となります。この繰り返しが手順4に相当します。そこでまずは全体の流れを図で見てみます。
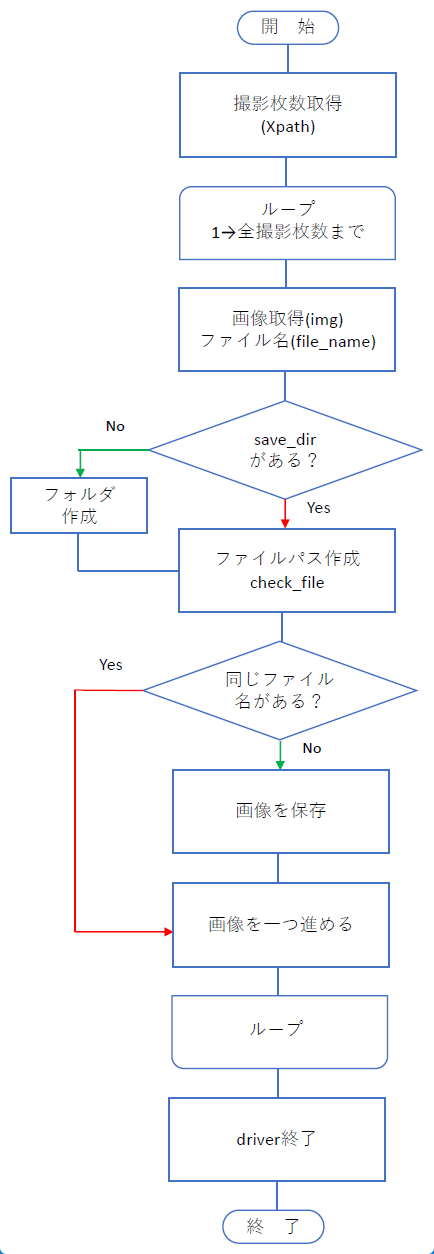
手順4の繰り返しは図中のループに対応します。この中に手順2と3が含まれています。これを踏まえてそれぞれのコードについて見ていきましょう。
キャプチャする枚数を取得する
まずはコード部分です。
# 撮影枚数を取得
img_num = driver.find_element(By.XPATH,"//*[@id='main']/form/table[2]/tbody/tr[2]/td/table/tbody/tr[3]/td[5]/input[3]")
img_num = img_num.get_attribute("value")
time.sleep(1)ここでは変数img_numに撮影枚数を入れています。同じ変数が続いていますが、枚数が入っている要素を特定した後にその属性を再代入しています。変数を別に作るのが面倒でしたので再利用しています。
さてその枚数ですが、前回までの考察で、火山カメラ画像のページにあるボタンなどの配置や機能を確認してきました。まずそれを思い出します。
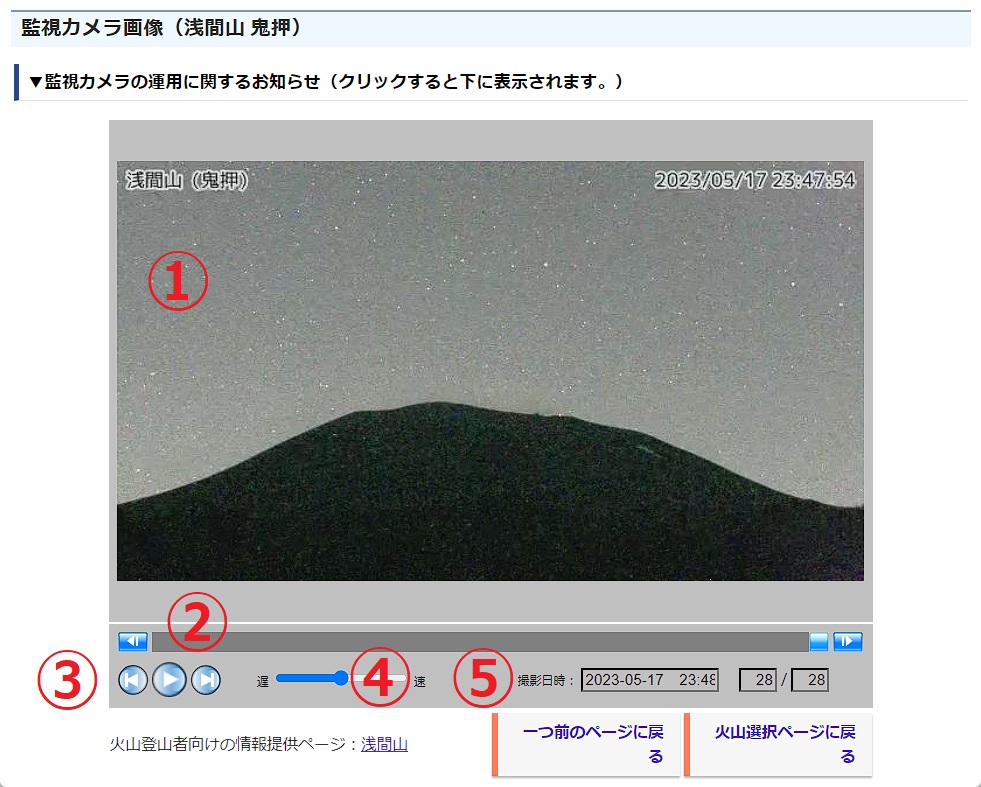
出展 気象庁 監視カメラ画像(浅間山(鬼押))
このうち、撮影に関する情報は⑤にまとめられていたのでしたね。そして⑤の右端にある数字が画像の総枚数に該当するのでした。ではこの28という数字を直接入力すれば良いのでは?と思われるかも知れませんが、これはちょっとまずいです。
何故なら火山によって撮影枚数は変わってくるからです。おおむね28~30枚なのですが、中には4枚、そして1枚という火山もあります。ですので固定した数字を入れるやり方は難しいです。
そこで前回記事でも登場したF12キーで起動する開発者ツールの出番です。⑤の撮影枚数の所にカーソルを合わせて検証をしてみると次のようになります。
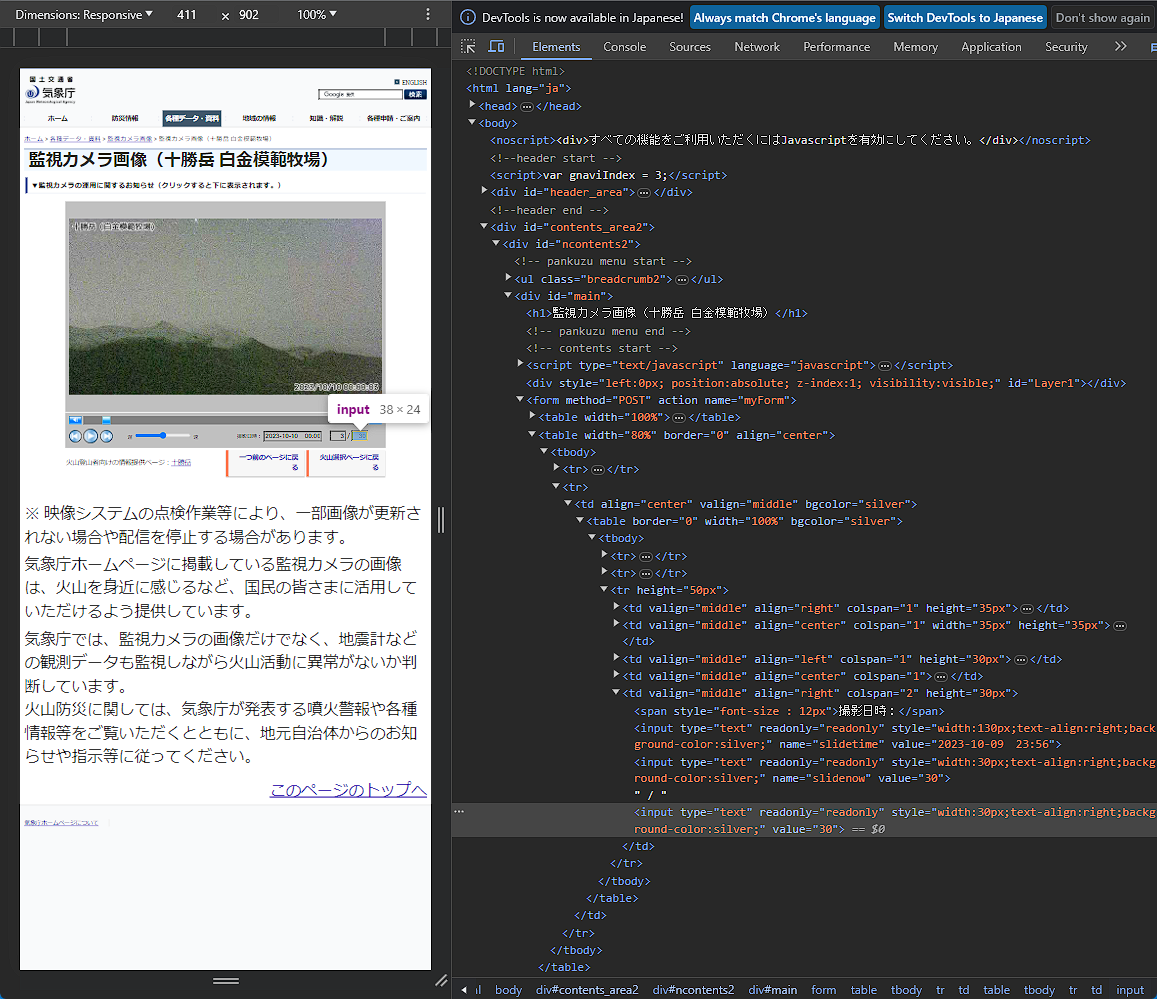
出展 気象庁 監視カメラ画像(十勝岳 白金模範牧場)
このハイライト部分を見てみると、input要素になっていますね。これはフォームの一部を形作る要素です。フォームとは、ざっくりした説明になってしまいますが、ユーザーから受け取った情報をサーバに送るために用意された入力部分です。
例えば検索サイトで何かキーワードを打ち込むとき、それを入力する専用の枠がありますよね?そして入力が終わったら送信するためのボタンをクリックあるいはタップされるかと思いますが、あれらがフォームを構成する部品ということです。
input要素はそのようなものの内、テキスト入力をするための枠、つまりテキストボックスということになります。
テキストボックスなので何か入力できそうに見えますが、readonly属性が入っているのでそれはできません。情報を表示するための枠ということなんですね。そして撮影枚数はどうやらvalue属性の値になっているようですね。ですのでこれを取り出してやります。
XPathロケータで指定する
撮影枚数を取り出すために特定すべきinput要素とその属性は分かりました。後はその指定方法です。前回同様cssセレクタでできそうですが、何だか複雑そうです。
というのも、先のハイライト部分のすぐ上を見てください。同じinput要素が二つありますよね?これは⑤の撮影日時と現在表示している画像の現在の枚数に対応していますが、inputタグ、type属性、readonly属性、style属性にまで重複が見られます。これでは特定が難しいように見えます。おそらくできるとは思うのですが、別の方法からアプローチすることにします。ここではXPathロケータを使うことにしました。
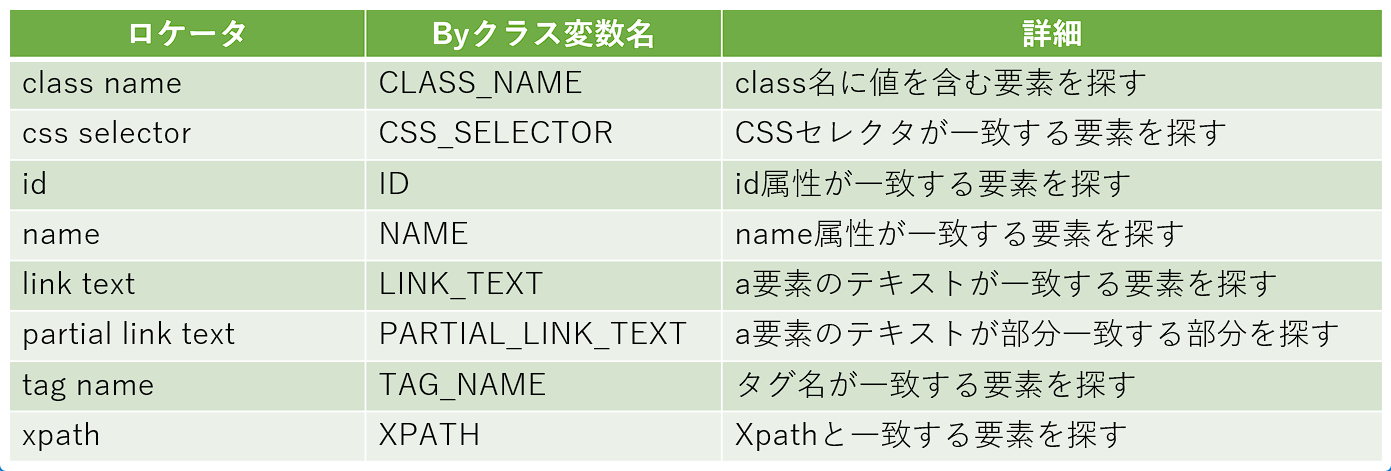
Selenium公式サイト「要素を探す」にByクラス変数名との関連を追加
ちょっと前回の復習ですが、Seleniumで要素を取得するにはfind_elementメソッドを利用します。そのための引数に必要となるのが要素を識別する方法、ロケータでしたね。
そこでXPathについてですが、これはXML文書でその位置を特定するために決められたルールで、文書をツリー構造に見立てて解釈し、その経路を指定してやることで特定を可能にするものです。ただ私もあまり深くは分かっていません。この辺りの話はJavascriptやDOM(Document Object Model)と関係性が強いようです。
さてXPathをどのように求めれば良いのかということですが、開発者ツール画面で該当のタグにハイライトして右クリックをします。するとCopy XPathあるいはCopy Full XPathと出てきますからどちらかを選択します。そしてそれをメモ帳か何かに貼り付けると以下の文字列が得られます。
//*[@id="main"]/form/table[2]/tbody/tr[2]/td/table/tbody/tr[3]/td[5]/input[3]こちらはFullではない方のXPathです。何やらやたら長い呪文のような文字列が出てきましたが、この文字列には、idがmainである要素に飛んでくれ、飛んだらその直下にform要素があるはずだ、それを辿っていくとtable要素が二つある、その内の二つ目を選んでくれ、そうするとそこにtbody要素がある。tbody要素には二つのtr要素がある、なのでまた二つ目を進んでくれ、すると一個のtd要素がある。それを辿るとまたtable要素がありまたtbody要素がある。今度はtr要素が三個も出てくる、その三番目を行くとなんとtd要素が五つも待ち構えてる。しかし慌てずその五番目を開けてほしい。するとそこにinput要素という名のお宝が三つある。その三番目のお宝こそが探し求めていたinput要素なのであった。~fin~
とそれはそれは素敵な冒険譚が内包されています。要は目的地へのルートを表現していることになります。開発者ツールのタグは展開したり畳んだりもできますので、一つ一つ追っていくとその意味が見えてくるかと思います。冒頭のコードを再掲します。
# 撮影枚数を取得
img_num = driver.find_element(By.XPATH,"//*[@id='main']/form/table[2]/tbody/tr[2]/td/table/tbody/tr[3]/td[5]/input[3]")
img_num = img_num.get_attribute("value")
time.sleep(1)input要素が特定できましたから、後は撮影枚数であるvalue属性にアクセスして取得完了です。
画像の読み込み
続いて画像読み込みです。先ほど直接URLにアクセスすると述べましたが、その場所はやはり開発者ツールを使うことで特定できます(右クリックメニューから「ページのソースを表示(Ctrl+U)」でも表示できます)。
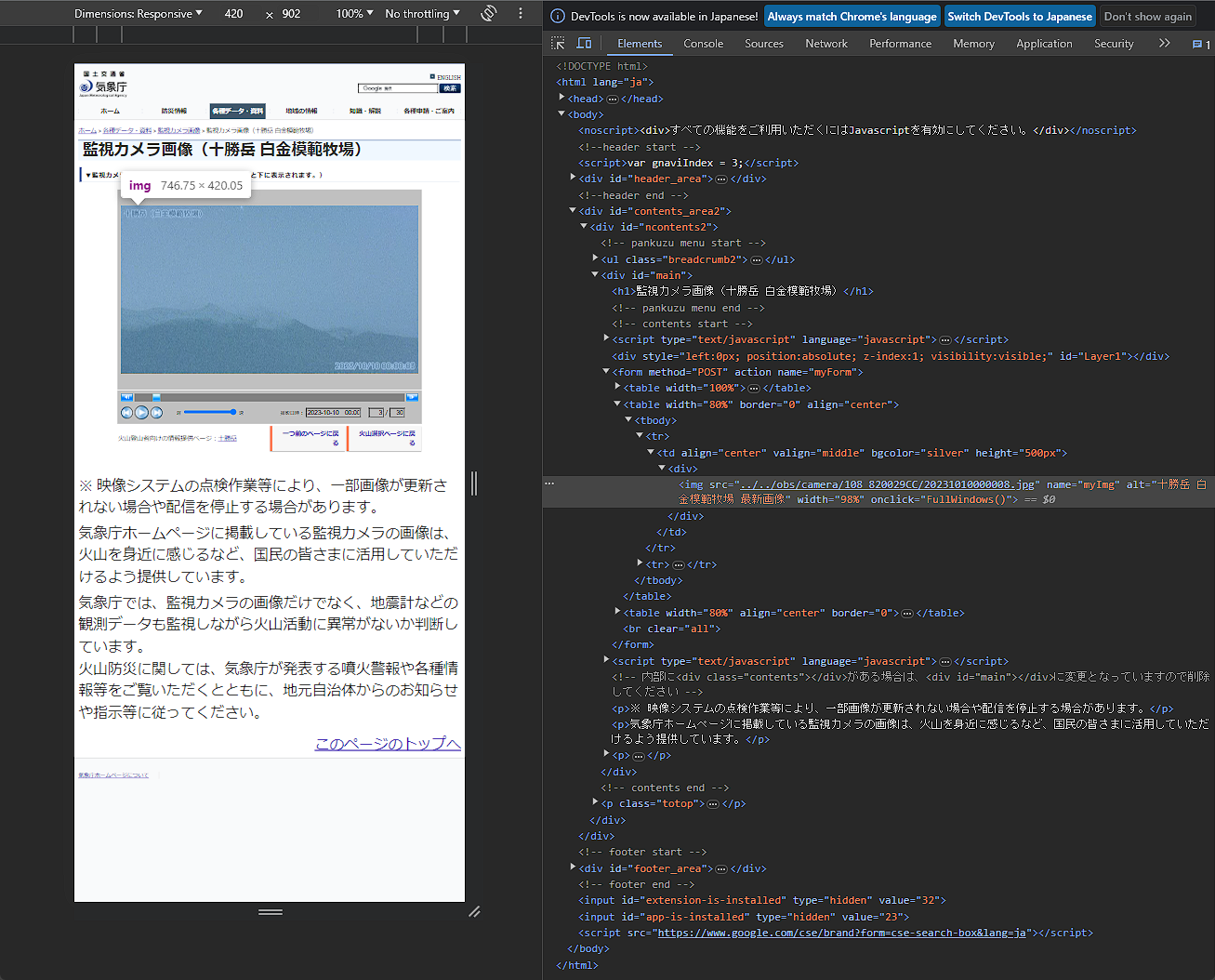
出展 気象庁 監視カメラ画像(十勝岳 白金模範牧場)
こちらは火山画像の部分を検証した結果です。ハイライトされている部分には画像を表示させるためのimg要素が見えます。img要素はその画像の場所を示す情報をsrc属性で指定するのでしたね。つまりこの部分に今表示されている画像のURLが格納されているということです。実際画像を変えてみるとそれに対応してURLも変化します。
また開発者ツール上でそのURLにカーソルを合わせるとより詳しい情報も表示され、実はサイトで表示される画像はちょっとだけ拡大されていることも分かるかと思います(上の画像では左側の部分にもサイズに関する情報が出ていますね)。
加えてもう一つ、name属性も組み込まれているようです。
name="myImg"これはその要素に名前を付ける属性で、結果として要素の特定が容易になります。よってURLを読み込むために、まずimg要素で上の名前を持つものを探し、そのsrc属性を読み込めば良いことになります。
ここの要素は画像が切り替わるごとにsrc属性、つまりURLが当然ながら変化しますので一見特定が難しそうですが、name属性は固定されていますので特定が簡単です。
またalt属性は火山カメラ画像の名前に半角スペース、文字列「最新画像」を結合したものになっています。火山カメラ画像の名前はselect_volcanoという変数に入っていますから、alt属性を利用しても特定ができると思います。
これも踏まえて撮影部分のコードの前半部分を見ていきましょう。
for i in range(int(img_num)):
img_tag = driver.find_element(By.NAME,"myImg")
img_url = img_tag.get_attribute("src")
img = requests.get(img_url)
file_name = os.path.basename(img_url)レシピに則り、撮影枚数分だけ画像保存作業を繰り返しますのでfor文を使います。range関数の引数は整数ですからint関数で整数型に変換してやります。続いてimg_tagに特定した画像要素を入れ、取り出したsrc属性(URL)をimg_urlに代入します。
次に得られたURLにアクセスして画像を保存する作業です。まず
img = requests.get(img_url)ですが、requestsモジュール(別途インストール必要)を利用して、このURLの内容が欲しいというHTTPリクエストをサーバに送信しています。そしてサーバから返ってきた内容(画像データ)がimgに格納されるといった具合になります。これでデータは手元に入りました。
保存するフォルダを指定
データを手に入れて次に行うことは、その受け入れ準備です。まず画像データのファイル名を決めますが、ここはダウンロードしたファイル名をそのまま取り出しています。ツールでハイライトした部分を見ると、ファイル名は年月日に加えて秒といった時系列情報で構成されており、一意性があるので使わせてもらうこととします。
ファイル名を取り出すには標準ライブラリであるos.pathモジュールのbasenameメソッドを使います。
file_name = os.path.basename(img_url)これでfile_nameにファイル名が入りました。ファイル名が決まりましたからそれを自分のPCのどのフォルダに保存するかを指定します。
# 保存ディレクトリの作成
# 取得した火山名を使う
save_dir = os.path.join(dir_path,select_volcano)こちらもos.pathモジュールを利用します。ここではjoinメソッドを使いました。これは引数に入れたファイルパスを結合する機能を持っています。
引数のうち、dir_pathはブロック2で決めておいたパスでしたね。またselect_volcanoは今見ている火山名ですから、ここで結合されたファイルパスは
(適当なディレクトリ)/volcano_camera/select_volcanoとなり、全ての火山カメラ画像はvolcano_cameraというフォルダ直下に置かれ、それぞれの火山名に対応したフォルダ下に保存されることになります。こうして画像を保存するフォルダ名も決まり、save_dirに格納されました。
フォルダを作成する
ところで、save_dirが決まったのは良いのですが、この時点では実際にこのファイルパスに対応するフォルダが存在しているかは分かりません。ここでのsave_dirは画像を保存することを予定しているファイルパスに過ぎません。
なのでこのフォルダが実際に存在するかを確認し、もしそれが存在していなければフォルダを作る必要が出てきます。それを行うのが次のコードということです。
# if not文で判断→フォルダがない→False→if notはTrue→フォルダを作る
if not os.path.isdir(save_dir):
os.makedirs(save_dir)ファイル操作に関する作業ですからos.pathモジュールのメソッドが次々と現れます。まずisdirメソッドはディレクトリ(フォルダ)の存在確認を行います。もし存在していればTrue、そうでなければFalseが返ります。
またmakedirsメソッドは、引数のディレクトリをまとめて作るメソッドです。おそらく初回起動時にはvolcano_cameraフォルダが無い状態だと思いますので、それも考慮しています。一つのフォルダを作る場合であれば、makedirメソッドを適用します。
そしてisdirメソッドの結果をif not文で判定し、フォルダがなければ作るようにしています。not演算子が入るのでisdirメソッドの結果がひっくり返ることに注意が必要です。
isdirメソッドが・・・
- True → not → False → if文の中身は実行しない
(フォルダはすでに存在しているので、作成しない) - False → not → True → if文の中身を実行する
(フォルダが存在しなかったので、新たに作成する)
notが入るとちょっとややこしいと感じられるかも知れません。色々なコードの書き方があるかと思いますので、素直にif文にしてisdirの結果がFalseの場合にフォルダ作成処理を行うようにしても良いでしょう。
保存を実行
# 撮影の重複をチェック
check_file = os.path.join(save_dir,file_name)
# if notで判定する
# 条件が真ならif notは偽を返す
# 条件が偽ならif notは真を返す
# ファイルがない=撮影していない=if notがTrue=Trueの処理=キャプチャする
if not os.path.isfile(check_file):
with open(check_file,"wb") as f:
f.write(img.content)
# 次の時間に移動
forward.click()
time.sleep(1)
driver.quit()
print("終わりました")いよいよ最後のコード部分です。ここまでの作業で画像のファイル名と保存するフォルダが決まりました。ですので後は保存するだけです。そこで再びjoinメソッドを使ってファイル名とフォルダを関連付けます。これが保存するファイルパスです。
変数名をcheck_fileとしてありますが、これは再度火山画像にアクセスした時に同じ画像(=ファイル名)の重複をチェックし、もし同じ画像であれば保存処理をスキップするためです。
火山画像はおおむね2分ごとに撮影した28~30枚の枚数で構成されており、例えば30分後に再アクセスしてキャプチャをしようとするとざっくり半分は画像が被ることになり、スキップ処理はあった方が良いだろうと思いましたのでそのように実装しています。そのための構文として先ほどと同様にnot演算子を使ったif not文を選択しています。そして中身の
with open(check_file,"wb") as f:
f.write(img.content)が画像保存を行うコードです。ここのコードの一行目は、check_fileというファイル名を持つファイルオブジェクトfをバイナリ書き込みモード(wb)で開いてね、ということを示しており、組み込みのopen関数を利用します。
そしてwith文の中身である二行目でrequestsで取得した画像データをfに書き込み、ファイルを閉じるという作業を行っています。contentメソッドでバイナリデータを取り出しています。画像はテキストデータではなくバイナリ形式ですから、型を合わせる必要があります。
Pythonでは、一度ファイルオブジェクトを作成してそこにデータを入れてから読み書きを行うようになっているようです。オブジェクトに対する操作はメソッドでしたから、読むときにはreadメソッド、書き込むときにはwriteメソッドが用意されています。
なのでここでのオブジェクトはあくまでも入れ物ですから、名前は基本何でも良いということになります。別にfにこだわる必要はなくvolcanoとかでも良い訳です。この辺りのコード解説は様々なサイトで見られますが、簡単な名前にした方が楽だし分かりやすいということでfにしていることが多いと思われます。ただし、with文内で名前を揃える必要があることに注意です。
またファイル読み書きの後にファイルオブジェクトを閉じる必要が出てきますが、with文を使うことでその処理を自動的にやってくれていることも押さえておきましょう。
# 次の時間に移動
forward.click()
time.sleep(1)ゴールが近付いてきました。画像保存後は、早送りボタンをクリックするメソッドであるclick()を使って画像を一枚次の時間のものに切り替えてからループの先頭に戻り、同様に保存処理を行います。すぐに次の処理に行くのではなく、time.sleep(1)を入れて1秒間隔を空けるようにしました。
ただコードを見直すと、最後の枚数の処理を終えた後にもクリック動作が入ってしまっているでしょうか…。直接この動作がプログラムに影響を与える訳ではないですが(クリックしても画像は最新のものから切り替わらないので)、if文を入れて処理を分岐するべきだったかも知れません。
driver.quit()
print("終わりました")保存が完了した後は、quitメソッドでdriverを終了し、ウインドウを閉じます。また「終わりました」とメッセージを出して一連の作業が終了したことが分かるようにしています。
これでブロック5の動作、そして全ブロックの動作が完了しました。
まとめです
Pythonによる火山カメラ画像のキャプチャについて、今回を含め全七回の連載をお送りしました。初回の記事から一年以上が経過してしまいましたが、完結させることができて良かったです。
プログラムは思った通りに動いてくれましたが、個人的にはまだまだ改善したい点がそれなりにあります。一つはアクセスした時間帯に撮影されていない火山があることです。この時、撮影枚数欄が空白となってしまいプログラムは枚数を取得できないのでエラーが発生します。
このエラーへの対応は実装しないといけないかなと思っています。そしてもう一つはプログラムの例外処理(try~except)を全く考えていないことです。
このプログラムでは見たい火山カメラを番号に置き換えて入力し、その値から火山を選択していますが、その時に許容される値はリストにある番号のみです。例えば私みたいな逆張り人間が平仮名やリスト以外の番号を入力したときにきちんとメッセージを出して再度入力をさせる仕組みが必要です。
何かを入力させるプログラムに例外処理を入れていないのは、本当はダメなことだと思います。ただ適用するならブロック3なのですが、ここのループ処理がややこしくて例外処理を両立させる方法が全然分からず諦めた、というのが実情です。良いアイデアが浮かんだらまた試してみたいと思います。
現在では少しプログラムを改良してブラウザウインドウを開かず、バックグラウンドで動作させてキャプチャしたり、火山一つをキャプチャして終わりではなく、あらかじめ見たい火山リストを作成しておいてそれを読み込んで連続キャプチャする派生版も作っています。後者は改めて記事を書くかも知れません。
備忘録としての意味合いが強い内容ですが、自分なりにプログラム構築に関する考え方を細かいところまで記していると思いますので、そういった点でほんの少しでもお役に立つことがあれば幸いです。あなたもPythonで何かプログラムを書いてみませんか?

