
こんにちは、管理人のアカツキです。
今回から新しく「副産物」カテゴリを新設しました。メインの防災とは少し趣が違いますが、こちらにも記事を投稿していくつもりです。当面はプログラミング、特にPython(パイソン)の記事を予定しています。
カテゴリを新設したいきさつや、私のプログラミングの経験などについてはカテゴリページにまとめてありますので、参考にして頂ければと思います。
とはいえ、ざっくり言うと素人が作ったものという認識で間違いございません。自身の備忘録・勉強録という意味もありますが、何よりPythonを勉強されている方、Pythonで何かをやってみたいという方に少しでもお役に立てる情報があればと考えています。
第一回目は「Pythonによる火山カメラのキャプチャ」です。単にコードを示すだけでなく、じっくり解説していこうと考えていますので連載を予定しています。回数は今のところ未定ですが、コードを役割別にブロック分割していますので、それぞれのブロックごとに取り上げていく形になると思います。
(2023.10.10 追記)
本日最後の記事を投稿し、全七回の連載となりました。

前置きが長くなりました。早速コードを見ていきましょう。
火山カメラキャプチャ・コード
"""
JMA火山監視カメラキャプチャ Ver.1.01
・JMAの火山監視カメラ画像をキャプチャする
・連続キャプチャを実施する(重複はスキップ)
・火山名をリストから選択する
・最初のリストはよくアクセスすると思われる火山
・火山リストをアップデート(20220727更新分)
"""
# ブロック1
from selenium import webdriver
from selenium.webdriver.chrome import service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import os
import requests
import time
# ブロック2
dir_path = "(適当なディレクトリ)/volcano_camera/"
fav_volcano = {1:'十勝岳 白金模範牧場',
2:'阿蘇山 草千里',
3:'桜島 牛根',
4:'諏訪之瀬島 寄木',
5:'その他'}
area_volcano = {1:'北海道',
2:'東北地方',
3:'関東・中部地方',
4:'伊豆・小笠原諸島',
5:'九州地方',
6:'戻る'}
hokkaido_volcano = {1: 'アトサヌプリ 北東山麓', 2: 'アトサヌプリ 硫黄山駐車場北',
3: 'アトサヌプリ 屈斜路湖南', 4: '雌阿寒岳 上徹別',
5: '雌阿寒岳 阿寒富士北', 6: '大雪山 忠別湖東',
7: '大雪山 旭岳姿見2', 8: '十勝岳 白金模範牧場',
9: '十勝岳 避難小屋南東', 10: '樽前山 別々川',
11: '倶多楽 414m山', 12: '倶多楽 地獄谷',
13: '有珠山 東湖畔', 14: '有珠山 月浦',
15: '北海道駒ヶ岳 鹿部公園南東', 16: '北海道駒ヶ岳 赤井川',
17: '北海道駒ヶ岳 剣ヶ峯', 18: '恵山 高岱',
19: '恵山 火口原', 20: '戻る'}
tohoku_volcano = {1: '岩木山 百沢東', 2: '八甲田山 大川原', 3: '八甲田山 地獄沼',
4: '十和田 銀山', 5: '秋田焼山 栂森', 6: '岩手山 柏台',
7: '岩手山 黒倉山', 8: '鳥海山 上郷2', 9: '栗駒山 大柳',
10: '栗駒山 展望岩頭', 11: '蔵王山 遠刈田温泉', 12: '蔵王山 上山金谷',
13: '蔵王山 刈田岳', 14: '蔵王山 御釜北', 15: '吾妻山 上野寺',
16: '安達太良山 若宮', 17: '安達太良山 鉄山', 18: '磐梯山 剣ケ峯',
19: '磐梯山 櫛ヶ峰', 20: '戻る'}
kanto_tyubu_volcano = {1: '那須岳 湯本ツムジケ平', 2: '那須岳 日の出平北', 3: '日光白根山 歌ヶ浜',
4: '日光白根山 上小川', 5: '草津白根山 奥山田', 6: '草津白根山 逢ノ峰山頂',
7: '草津白根山 草津', 8: '浅間山 鬼押', 9: '浅間山 追分',
10: '新潟焼山 宇棚', 11: '弥陀ヶ原 芦峅', 12: '焼岳 中尾峠',
13: '乗鞍岳 乗鞍高原', 14: '御嶽山 三岳黒沢', 15: '御嶽山 奥の院',
16: '白山 白峰', 17: '富士山 萩原', 18: '箱根山 宮城野',
19: '箱根山 大涌谷', 20: '箱根山 箱根峠', 21: '伊豆東部火山群 大原',
22: '伊豆東部火山群 大崎', 23: '戻る'}
izu_ogasawara_volcano = {1: '伊豆大島 北西外輪', 2: '伊豆大島 中央火孔北', 3: '新島 式根',
4: '神津島 前浜南東', 5: '三宅島 坪田', 6: '三宅島 神着',
7: '三宅島 山頂火口北西', 8: '八丈島 楊梅ヶ原', 9: '青ヶ島 手取山',
10: '戻る'}
kyusyu_volcano = {1: '鶴見岳・伽藍岳 塚原無田', 2: '九重山 上野', 3: '九重山 星生山北尾根',
4: '九重山 飯田大原', 5: '阿蘇山 草千里', 6: '阿蘇山 車帰',
7: '阿蘇山 南阿蘇村', 8: '雲仙岳 野岳', 9: '雲仙岳 垂木台地南',
10: '霧島山 猪子石(新燃岳)', 11: '霧島山 猪子石(御鉢)', 12: '霧島山 御鉢火口南縁',
13: '霧島山 高原西麓', 14: '霧島山 八久保', 15: '霧島山 韓国岳',
16: '霧島山 えびの高原', 17: '霧島山 硫黄山南', 18: '桜島 牛根',
19: '桜島 東郡元', 20: '桜島 垂水荒崎', 21: '桜島 中央港新町',
22: '薩摩硫黄島 岩ノ上', 23: '口永良部島 本村西', 24: '口永良部島 屋久島吉田',
25: '諏訪之瀬島 寄木', 26: '諏訪之瀬島 キャンプ場', 27:'戻る'}
area_volcano2 = {'北海道':hokkaido_volcano,
'東北地方':tohoku_volcano,
'関東・中部地方':kanto_tyubu_volcano,
'伊豆・小笠原諸島':izu_ogasawara_volcano,
'九州地方':kyusyu_volcano}
# ブロック3
# メニューを行き来するためのフラグを設定
Flag = True
while Flag:
for vkey1, vvalue1 in fav_volcano.items():
print(f"{vkey1} : {vvalue1}")
select_vkey1 = input("火山を選択してください [No.?] >>> ")
select_vkey1 = int(select_vkey1)
select_vvalue1 = fav_volcano[select_vkey1]
# 1~6を選んだ場合の処理→値を取得してループ離脱
if not select_vvalue1 == "その他":
select_volcano = select_vvalue1
break
elif select_vvalue1 == "その他":
# もう一つwhileを入れる
while Flag:
for vkey2, vvalue2 in area_volcano.items():
print(f"{vkey2} : {vvalue2}")
select_vkey2 = input("地域を選択してください [No.?] >>> ")
select_vkey2 = int(select_vkey2)
select_vvalue2 = area_volcano[select_vkey2]
if select_vvalue2 == "戻る":
# 再度前の画面に戻る
break
elif select_vvalue2 != "戻る":
for vkey3,vvalue3 in area_volcano2[select_vvalue2].items():
print(f"{vkey3} : {vvalue3}")
select_vkey3 = input("火山を選択してください [No.?] >>> ")
select_vkey3 = int(select_vkey3)
select_vvalue3 = area_volcano2[select_vvalue2][select_vkey3]
if not select_vvalue3 == "戻る":
# 火山名を取得してループを抜ける
select_volcano = select_vvalue3
Flag = False
elif select_vvalue3 == "戻る":
# 地域選択画面に戻る
pass
print(select_volcano,"を選びました")
print(select_volcano,"にアクセスします")
# ブロック4
chrome_driver = "(適当なディレクトリ)/chromedriver.exe"
chrome_service = service.Service(executable_path=chrome_driver)
driver = webdriver.Chrome(service=chrome_service)
wait = WebDriverWait(driver=driver, timeout=10)
driver.implicitly_wait(5)
driver.set_window_position(50,50)
driver.set_window_size(1400,1300)
# JMAの監視カメラ画像のページに直接アクセスする
driver.get("https://www.data.jma.go.jp/vois/data/tokyo/volcam/volcam.php")
# wait.until(EC.presence_of_all_elements_located)
# 選択された火山カメラを開く
volcam = driver.find_element(By.LINK_TEXT,select_volcano)
volcam.click()
# wait.until(EC.presence_of_all_elements_located)
# スライダを左端に移動
driver.find_element(By.CSS_SELECTOR,"img[src='./icon/player/oldest.png']").click()
# 早送りボタンを取得
forward = driver.find_element(By.CSS_SELECTOR,"img[src='./icon/player/next-frame.png']")
# ブロック5
# 画像を保存する(繰り返し)
# 撮影枚数を取得
img_num = driver.find_element(By.XPATH,"//*[@id='main']/form/table[2]/tbody/tr[2]/td/table/tbody/tr[3]/td[5]/input[3]")
img_num = img_num.get_attribute("value")
time.sleep(1)
for i in range(int(img_num)):
img_tag = driver.find_element(By.NAME,"myImg")
img_url = img_tag.get_attribute("src")
img = requests.get(img_url)
file_name = os.path.basename(img_url)
# 保存ディレクトリの作成
# 取得した火山名を使う
save_dir = os.path.join(dir_path,select_volcano)
# if not文で判断→フォルダがない→False→if notはTrue→フォルダを作る
if not os.path.isdir(save_dir):
os.makedirs(save_dir)
# 撮影の重複をチェック
check_file = os.path.join(save_dir,file_name)
# if notで判定する
# 条件が真ならif notは偽を返す
# 条件が偽ならif notは真を返す
# ファイルがない=撮影していない=if notがTrue=Trueの処理=キャプチャする
if not os.path.isfile(check_file):
with open(check_file,"wb") as f:
f.write(img.content)
# 次の時間に移動
forward.click()
time.sleep(1)
driver.quit()
print("終わりました")火山カメラキャプチャで出来ること
先ほどご紹介したのが火山キャプチャのソースコードになります。先頭のコメントブロックにも示してありますが、このプログラムが具体的にどのような機能を有しているかを整理してみます。
JMA火山監視カメラキャプチャ Ver.1.01(volcano_capture.py)
- 気象庁(JMA)が提供している火山監視カメラ画像について、
任意の火山画像をキャプチャ(保存)する - キャプチャする火山名はリストから選択する(番号を入力して指定)
- 画像を保存するフォルダ・ファイル名は自動で生成する
- 火山リストを更新(2022.7.27 カメラ追加のプレスリリース)
これだけですと少しイメージが涌かないかも知れませんね。そこで実際にプログラムを動かしてみました。このような感じで動きます。
ご覧になられたように、最初に入力した火山名を取得してからブラウザ(ここではGoogle Chrome)が自動的に立ち上がり、自動的に該当する火山監視カメラ画像にアクセスし、画像をキャプチャしている様子が確認できるかと思います。
また、火山名はあらかじめ設定されたリスト内から番号で選択するようにしています。JMAで提供されている全ての火山に対応しています。最初のリストは多くアクセスするであろうお気に入りリストになっており、手早く火山を指定できるようにしています。以上が主な処理の内容です。
実際に動作を見てどうでしたか?びっくりしますよね。だって自動でブラウザが立ち上がって勝手に動いているのですから。私も驚きました。それはこのツールを作る前に思い立ったは良いが本当にそんなことができるのかと思って調べたら本当にできる可能性を感じた驚きと、実際に自分でコードを組んでみると本当に動作したという二重の驚きです。
この勝手に動いている動作を最も印象付けているのが、火山カメラの画像が刻々と変わっていくところだと思います。
実はこの動作、たった1行のコードで動いています。
forward.click()何となく意味がお分かりになるかと思いますが、これはforwardをクリックしなさい、という命令になります。ではforwardの部分とは?ということになりますが、こちらを指します。
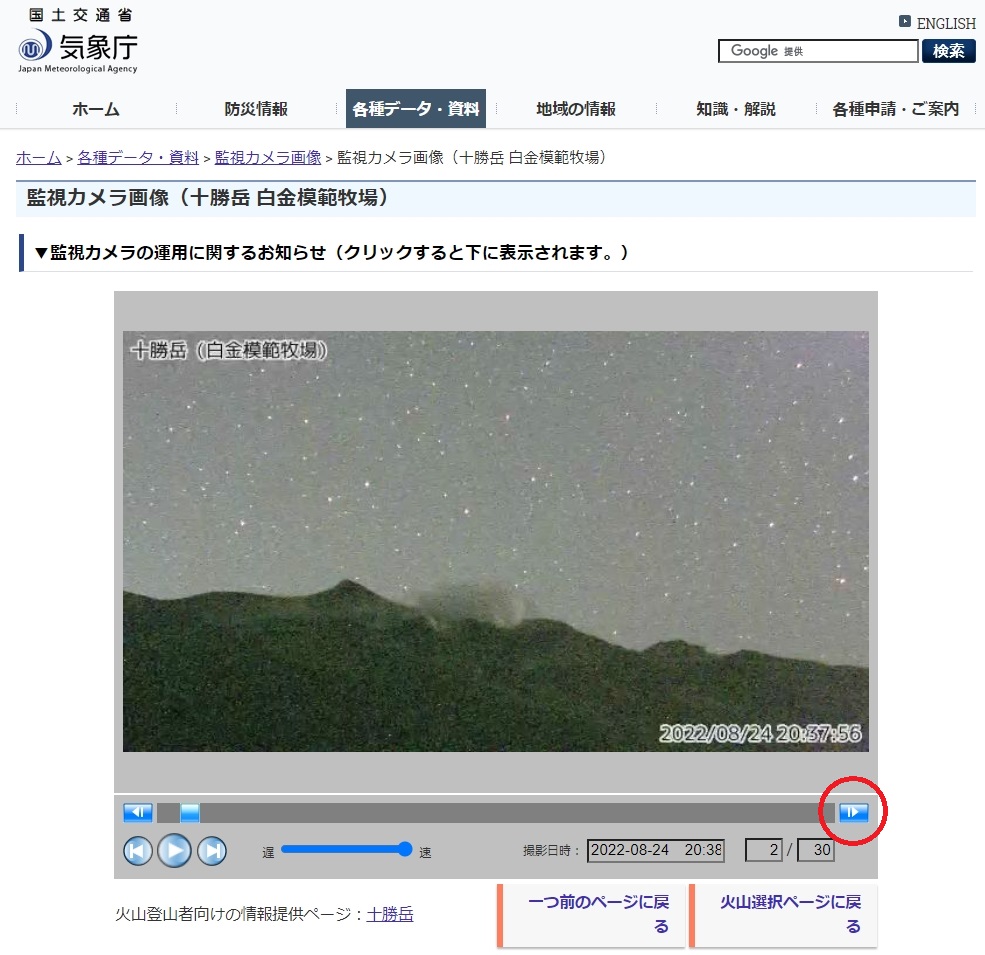
出展 気象庁 監視カメラ画像(画面は十勝岳 白金模範牧場)
このボタンは、クリックすると次の時間の火山画像に切り替える働きをします。実際にはボタンの名称はforwardではない別の名前があてられていますが、Python上でその名前を指定して探し、見つかったものをforwardに入れて操作しています。
一つ例を挙げてみましたが、Pythonの凄さといいますか、難しそうに見える機能が、わずか1行のシンプルなコードで実現できることを取り上げてみました。ほんの片りんですが、Pythonって思ったよりも使いやすいのでは?ということを感じてもらえたかと思います。
それでは実際にプログラムの中身について解説をしていきます。先に述べましたが、コードにはあらかじめその役割ごとにブロック番号を付けて分割しています。
ブロック一覧とその役割
- プログラムで使用するモジュールの呼び出し
- ファイル保存や火山名の選択に使う変数やデータ
- 火山選択メニュー
- 選択された火山カメラをブラウザで読み込む
- キャプチャした画像の保存処理
今回のその1番目である「プログラムで使用するモジュールの呼び出し」について見ていきます。
ブロック1・使用モジュール
# ブロック1
from selenium import webdriver
from selenium.webdriver.chrome import service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import os
import requests
import timeモジュールはSeleniumを中心に使用
ブロック1では、本プログラムで使用するモジュール(クラス)を読み込んでいます。Pythonではある特定の用途に対応した関数などがまとまった形で提供されており、読み込むことでその機能を利用できます。これはモジュールと呼ばれ、ほとんどのプログラムでお世話になることが多いかと思います。
一方でそのモジュールがまとまったものはライブラリと呼ばれます。ただ、モジュールとライブラリはそこまで四角く意味を区切られている訳ではないようです。
ここでは、Selenium(セレニウム)に関連するモジュールが大量に呼び出されていますので、Seleniumをライブラリ、その他をモジュールとして取り扱っていきます。
Seleniumライブラリ
Webブラウザの操作はSeleniumライブラリ
from selenium import webdriver
from selenium.webdriver.chrome import service
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as ECまずはこちらのseleniumなんちゃらとかいう文字列の集団です。先ほども少し触れましたが、Seleniumライブラリを使用します。このライブラリを使うことでWebブラウザを自動的に操作することが可能になります。
本プログラムではその動作としてブラウザを自動的に立ち上げ、サイトにアクセスして特定の画像を保存する、といった作業を行います。
言うなれば、ほぼすべてがWebブラウザの操作に関わっています。ですのでSeleniumライブラリはプログラムの要となります。その分読み込むモジュールも多くなっているというわけです。
それでは一つ一つのモジュールについてその意味を見ていきます。
webdriver: これが無いとブラウザが動きません
from selenium import webdriver最初の一文です。seleniumライブラリからwebdriverモジュールをインポートしなさい、という命令です。ブロック4の先取りになりますが、このようにwebdriverのオブジェクトを作成し、各ブラウザに対応したdriverを代入してブラウザをコントロールする算段になっています。
# 使用するブラウザのdriverを指定
chrome_driver = "(適当なディレクトリ)/chromedriver.exe"
chrome_service = service.Service(executable_path=chrome_driver)
driver = webdriver.Chrome(service=chrome_service)webdriver(モジュールとは別です)はSeleniumとwebブラウザ間の通信を処理するためのもので、chromeやedgeといった各ブラウザがそれぞれに持っているプログラムです。
実はSelenium単独ではブラウザを操作できないんですね。webdriverの助けがあって初めてそれが可能になります。
つまりwebdriverモジュールを読み込んでも、読み込むものがないとダメ、ということになります。使用するブラウザに合ったwebdriverも別にダウンロードする必要がある、ということになります。そしてSeleniumではこのブラウザごとのwebdriverをdriver(ドライバ)と呼んでいるようです。
現段階では、ドライバを使えるようにする準備と解釈すれば良いと思います。
service: Selenium4からはこちらを使います
from selenium.webdriver.chrome import service次にserviceモジュールについてです。こちらはドライバのプロセスを管理(起動や終了)するために導入されたモジュールです。
ですので、driverをダウンロードして保存してあるファイルパスを、生成したserviceオブジェクトに渡して管理してもらう必要があります。先ほどのコードでしれっと登場していましたが再掲します。
chrome_driver = "(適当なディレクトリ)/chromedriver.exe"
# executable_pathにdriverのパスを渡す
chrome_service = service.Service(executable_path=chrome_driver)
# webdriverオブジェクトにserviceを渡す(直接executable_pathを渡さない)
driver = webdriver.Chrome(service=chrome_service)その後、実際にブラウザをコントロールするwebdriverオブジェクトを生成するのですが、この引数serviceにさらに渡すことでdriverが機能するようになる仕組みになっています。
文を見ますと直接webdriverにexecutable_pathでdriverのパスを渡せば良いように見えますが、それはSelenium3までの構文です。Selenium4からは上記のような方法が推奨され、旧来の方法ではエラーが起こるようです。
Byモジュールでロケータを使えるようにします
from selenium.webdriver.common.by import By続いてはByモジュールです。このモジュールは、ロケータを使えるようにするためのものです。ではそのロケータとは何ぞや?ということですが、公式サイトには次のような記述があります。
A locator is a way to identify elements on a page.
出展 Selenium –Locator strategies–
It is the argument passed to the Finding element methods.
(ロケータは、ページ上の要素を識別する方法です。
検索要素のメソッドに渡される引数です。)
webページ上には実に様々な要素があります。たとえば見出しの部分とか、テキストとか画像とかですね。そして今やろうとしていることはwebブラウザを自動で操作することでした。
つまり私たちが通常行っている、ここをクリックしてリンク先に進む、といった作業をSeleniumにやってもらうということになります。
では具体的に人間の動作をどうやって再現するのかというと、その要素を探し出し、動作(クリックするなどの)命令を出せば良いことになります。
その要素を探すのに使われるのがロケータであり、ロケータを呼び出しているのがByモジュールということになります。実際にByモジュール(実体はby.pyというファイルです)の中身をテキストエディタで開くと八つのロケータ(Byクラス)が指定されていることがわかります。
ブロック4ではさらにロケータについて解説していきます。
webDriverWait: 待機処理を可能にします
from selenium.webdriver.support.ui import WebDriverWait本プログラムでは、自分のPCだけでなく、アクセスする先もあっての動作ということにご注意ください。たとえば指定したページを読み込んだ後に、ここの要素を抽出したいといったことが少なくないと思います。
そのような時、もしページ読み込みが完全に終わっていない場合もあるかも知れません。となればそれを待ってから要素を検索した方が確実に要素を取得できますよね。つまり待機処理が導入できればより良いプログラムが作れそうです。webDriverWaitはそのような待機を実現するためのクラスになり、生成したwebDriverWaitオブジェクトに対して待機メソッドを適用することができます。
また、Selenium4ではその待機について二つの方法が用意されています。
- 明示的な待機(Explicit Wait)
特定の条件が満たされるまで待機する - 暗示的な待機(Implicit Wait)
すべての要素取得時に待機する(設定は一度だけ)
本プログラムでは両方の待機を利用しています。特に明示的な待機は次のモジュールを導入して行っています。
expected_conditions: 明示的な待機条件を設定
from selenium.webdriver.support import expected_conditions as EC先ほどのwebdriverwaitと合わせて使うモジュールになります。expected(期待された、予想される)なconditions(条件)ですから、ある条件を満たすまで動作を待機するというのがこのモジュールの役割になります。
そのまま書いていると長いのでas ECとして短縮して使用できるようにするのが慣例のようです。
これについては具体例で見ていきます。関係するコードを抜き出しました。
wait = WebDriverWait(driver=driver, timeout=10)
# ブラウザによる処理(ページを開いたり要素をクリックなど)
wait.until(EC.presence_of_all_elements_located)
# until(メソッド, メッセージ='')webdriverwaitオブジェクトを作成し、それに対してuntilメソッドを適用しています。このメソッドの中には、更にECメソッドとメッセージ(オプション)が入ります。ECメソッドのみの使用が典型的でしょう。そして戻り値がFalseと評価されなくなるまでメソッドを呼び出すようになっています。ECメソッドはかなりの数が用意されています。今回使用したpresence_of_all_elements_locatedはその名前からすると、全ての要素が存在することを確認するまでwaitすることを期待するものです。
ただ…今回記事にするに当たってまた色々調べたのですが、ちょっとこのコードの有効性に疑問を持ち始めています。というのは、コードの有る無しで実際の挙動は変わらなかったからです。
プログラムでは、大元の監視カメラのサイトと、肝心の見たい火山カメラのページそれぞれにアクセスした後にこのコードを入れています。しかしそれらをコメントアウトしてプログラムを動かしてみてもトラブル無く動作するんですよね。
一方でこの二つのページがきちんと読み込まれていないと後の操作に支障をきたしますから、保険的な意味合いで一応コードを付けてあります。
しかし、こちらを見ますと使い方的にそもそもlocator((by,path)のタプル)が必要になっていますし、メソッドの意味も少なくとも一つの要素が存在するか、と書かれています。つまり先ほど赤字で示した部分はメソッド名を字面のまま解釈して期待される機能を私が書いたものでして、実際の意味はどうも違うらしい、ということです。
意図的にアクセス先からの応答が遅れる場合を作ってテストできれば良いのですが…ちょっとこの条件については疑問符付きで運用しています。
Selenium以外のモジュール
os: ファイルパスの操作を行います
import osようやくSeleniumライブラリを抜けました。残りはこのosとrequests、timeを含めて三つです。まずはosですが、標準で組み込まれているモジュールです。これを利用することで、ディレクトリを作成したり、ファイルパスの操作を行うことができます。
本プログラムでも画像を保存するフォルダや画像ファイル名の作成に利用しています。
requests: HTTP通信を行います
import requests続いてrequestsモジュールです。HTTP通信によってサーバにリクエストを送り、その返信であるリクエストを取得する機能を持っています。
対象サイトのurlに含まれている情報が戻ってきますので、テキストだけでなく、画像も取得できます。
img = requests.get(img_url)このようにプログラム中わずか一行のコードでrequestsを使っているに過ぎないのですが、これによってimgに画像そのものが格納されます。一行でも非常に重要な役割を担っていると言えます。
time: 一時停止に使用します
import time最後にtimeモジュールです。こちらもPython標準のモジュールになっており、現在時間の取得やプログラムの実行時間の測定に用いられます。
ただここではもう一つの機能である指定時間プログラムの処理を停止(sleepメソッドを使用)を利用しています。
time.sleep(秒数)
# 処理を3秒中断する
time.sleep(3)この方法はアクセスしているサーバに負荷をかけない配慮と言えます。
監視カメラ画像は数十枚ありますので、何もしないとPythonはあっという間にそれらにアクセスして処理をしてしまいます。しかし監視カメラ画像はそのような運用は想定しておらず、画像が存在する範囲で手動あるいは自動で切り替えて閲覧することを想定しています。
本プログラムではその自動切換え間隔も踏まえ、なるべく自然なアクセスになるような時間を設定して利用しています。ただtime.sleepの使用例を色々なサイトで見ていくと、サーバにアクセスするようなプログラムでは推奨していない方も少なくないようです。私はシチュエーション的に積極的に使用していますが、色々なやり方があるのだと思います。
まとめです
「Pythonによる火山カメラのキャプチャ」第一回目をお送りしました。
今回は主に使用するモジュールやクラスについて解説を行いました。とは言ってもまだブロック的には最序盤です。ブロックごとに解説をしていこうと思っていますので、おそらく全5回ほどの連載になろうかとは思います。
近年、Pythonを中心として第三次AIブームが起こっています。つい最近もキーワードテキストを入力するだけで驚くほど緻密な絵を出力するMidjourneyが話題になっていますよね。

そのような中で自分もPythonを使ってみたい、と思う方も増えているのではないかと思います。中には本プログラムのようにサーバにアクセスして必要な情報を自動的に取得したい、という想定をされている方もおられるでしょう。
このようにwebブラウザを操作してサーバにアクセスする技術はwebスクレイピングと呼ばれます。ただこれは相手のサーバに多大な負荷をかけてまで行うことではないと思います。あくまでも常識の範囲内で利用することが望まれるでしょう。
本プログラムの使用・改変は自由ですが、ぜひこの点を踏まえ、もしご利用をされる場合があれば、適切な利用をお願いします。

コメント