
こんにちは、管理人のアカツキです。プログラミング言語のPythonを利用して火山カメラ画像をキャプチャするプログラムについて解説を行っています。大分時間が経ってしまいましたが、続きです。
今回はキャプチャ作業の中身について迫っていきます。例によりまして前回までの記事はこちらです。

(再掲)火山カメラ・キャプチャ コード
こちらも例によりまして、全体のコードを再掲します。
"""
JMA火山監視カメラキャプチャ Ver.1.01
・JMAの火山監視カメラ画像をキャプチャする
・連続キャプチャを実施する(重複はスキップ)
・火山名をリストから選択する
・最初のリストはよくアクセスすると思われる火山
・火山リストをアップデート(20220727更新分)
"""
# ブロック1
from selenium import webdriver
from selenium.webdriver.chrome import service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import os
import requests
import time
# ブロック2
dir_path = "(適当なディレクトリ)/volcano_camera/"
fav_volcano = {1:'十勝岳 白金模範牧場',
2:'阿蘇山 草千里',
3:'桜島 牛根',
4:'諏訪之瀬島 寄木',
5:'その他'}
area_volcano = {1:'北海道',
2:'東北地方',
3:'関東・中部地方',
4:'伊豆・小笠原諸島',
5:'九州地方',
6:'戻る'}
hokkaido_volcano = {1: 'アトサヌプリ 北東山麓', 2: 'アトサヌプリ 硫黄山駐車場北',
3: 'アトサヌプリ 屈斜路湖南', 4: '雌阿寒岳 上徹別',
5: '雌阿寒岳 阿寒富士北', 6: '大雪山 忠別湖東',
7: '大雪山 旭岳姿見2', 8: '十勝岳 白金模範牧場',
9: '十勝岳 避難小屋南東', 10: '樽前山 別々川',
11: '倶多楽 414m山', 12: '倶多楽 地獄谷',
13: '有珠山 東湖畔', 14: '有珠山 月浦',
15: '北海道駒ヶ岳 鹿部公園南東', 16: '北海道駒ヶ岳 赤井川',
17: '北海道駒ヶ岳 剣ヶ峯', 18: '恵山 高岱',
19: '恵山 火口原', 20: '戻る'}
tohoku_volcano = {1: '岩木山 百沢東', 2: '八甲田山 大川原', 3: '八甲田山 地獄沼',
4: '十和田 銀山', 5: '秋田焼山 栂森', 6: '岩手山 柏台',
7: '岩手山 黒倉山', 8: '鳥海山 上郷2', 9: '栗駒山 大柳',
10: '栗駒山 展望岩頭', 11: '蔵王山 遠刈田温泉', 12: '蔵王山 上山金谷',
13: '蔵王山 刈田岳', 14: '蔵王山 御釜北', 15: '吾妻山 上野寺',
16: '安達太良山 若宮', 17: '安達太良山 鉄山', 18: '磐梯山 剣ケ峯',
19: '磐梯山 櫛ヶ峰', 20: '戻る'}
kanto_tyubu_volcano = {1: '那須岳 湯本ツムジケ平', 2: '那須岳 日の出平北', 3: '日光白根山 歌ヶ浜',
4: '日光白根山 上小川', 5: '草津白根山 奥山田', 6: '草津白根山 逢ノ峰山頂',
7: '草津白根山 草津', 8: '浅間山 鬼押', 9: '浅間山 追分',
10: '新潟焼山 宇棚', 11: '弥陀ヶ原 芦峅', 12: '焼岳 中尾峠',
13: '乗鞍岳 乗鞍高原', 14: '御嶽山 三岳黒沢', 15: '御嶽山 奥の院',
16: '白山 白峰', 17: '富士山 萩原', 18: '箱根山 宮城野',
19: '箱根山 大涌谷', 20: '箱根山 箱根峠', 21: '伊豆東部火山群 大原',
22: '伊豆東部火山群 大崎', 23: '戻る'}
izu_ogasawara_volcano = {1: '伊豆大島 北西外輪', 2: '伊豆大島 中央火孔北', 3: '新島 式根',
4: '神津島 前浜南東', 5: '三宅島 坪田', 6: '三宅島 神着',
7: '三宅島 山頂火口北西', 8: '八丈島 楊梅ヶ原', 9: '青ヶ島 手取山',
10: '戻る'}
kyusyu_volcano = {1: '鶴見岳・伽藍岳 塚原無田', 2: '九重山 上野', 3: '九重山 星生山北尾根',
4: '九重山 飯田大原', 5: '阿蘇山 草千里', 6: '阿蘇山 車帰',
7: '阿蘇山 南阿蘇村', 8: '雲仙岳 野岳', 9: '雲仙岳 垂木台地南',
10: '霧島山 猪子石(新燃岳)', 11: '霧島山 猪子石(御鉢)', 12: '霧島山 御鉢火口南縁',
13: '霧島山 高原西麓', 14: '霧島山 八久保', 15: '霧島山 韓国岳',
16: '霧島山 えびの高原', 17: '霧島山 硫黄山南', 18: '桜島 牛根',
19: '桜島 東郡元', 20: '桜島 垂水荒崎', 21: '桜島 中央港新町',
22: '薩摩硫黄島 岩ノ上', 23: '口永良部島 本村西', 24: '口永良部島 屋久島吉田',
25: '諏訪之瀬島 寄木', 26: '諏訪之瀬島 キャンプ場', 27:'戻る'}
area_volcano2 = {'北海道':hokkaido_volcano,
'東北地方':tohoku_volcano,
'関東・中部地方':kanto_tyubu_volcano,
'伊豆・小笠原諸島':izu_ogasawara_volcano,
'九州地方':kyusyu_volcano}
# ブロック3
# メニューを行き来するためのフラグを設定
Flag = True
while Flag:
for vkey1, vvalue1 in fav_volcano.items():
print(f"{vkey1} : {vvalue1}")
select_vkey1 = input("火山を選択してください [No.?] >>> ")
select_vkey1 = int(select_vkey1)
select_vvalue1 = fav_volcano[select_vkey1]
# 1~6を選んだ場合の処理→値を取得してループ離脱
if not select_vvalue1 == "その他":
select_volcano = select_vvalue1
break
elif select_vvalue1 == "その他":
# もう一つwhileを入れる
while Flag:
for vkey2, vvalue2 in area_volcano.items():
print(f"{vkey2} : {vvalue2}")
select_vkey2 = input("地域を選択してください [No.?] >>> ")
select_vkey2 = int(select_vkey2)
select_vvalue2 = area_volcano[select_vkey2]
if select_vvalue2 == "戻る":
# 再度前の画面に戻る
break
elif select_vvalue2 != "戻る":
for vkey3,vvalue3 in area_volcano2[select_vvalue2].items():
print(f"{vkey3} : {vvalue3}")
select_vkey3 = input("火山を選択してください [No.?] >>> ")
select_vkey3 = int(select_vkey3)
select_vvalue3 = area_volcano2[select_vvalue2][select_vkey3]
if not select_vvalue3 == "戻る":
# 火山名を取得してループを抜ける
select_volcano = select_vvalue3
Flag = False
elif select_vvalue3 == "戻る":
# 地域選択画面に戻る
pass
print(select_volcano,"を選びました")
print(select_volcano,"にアクセスします")
# ブロック4
chrome_driver = "(適当なディレクトリ)/chromedriver.exe"
chrome_service = service.Service(executable_path=chrome_driver)
driver = webdriver.Chrome(service=chrome_service)
wait = WebDriverWait(driver=driver, timeout=10)
driver.implicitly_wait(5)
driver.set_window_position(50,50)
driver.set_window_size(1400,1300)
# JMAの監視カメラ画像のページに直接アクセスする
driver.get("https://www.data.jma.go.jp/vois/data/tokyo/volcam/volcam.php")
# wait.until(EC.presence_of_all_elements_located)
# 選択された火山カメラを開く
volcam = driver.find_element(By.LINK_TEXT,select_volcano)
volcam.click()
# wait.until(EC.presence_of_all_elements_located)
# スライダを左端に移動
driver.find_element(By.CSS_SELECTOR,"img[src='./icon/player/oldest.png']").click()
# 早送りボタンを取得
forward = driver.find_element(By.CSS_SELECTOR,"img[src='./icon/player/next-frame.png']")
# ブロック5
# 画像を保存する(繰り返し)
# 撮影枚数を取得
img_num = driver.find_element(By.XPATH,"//*[@id='main']/form/table[2]/tbody/tr[2]/td/table/tbody/tr[3]/td[5]/input[3]")
img_num = img_num.get_attribute("value")
time.sleep(1)
for i in range(int(img_num)):
img_tag = driver.find_element(By.NAME,"myImg")
img_url = img_tag.get_attribute("src")
img = requests.get(img_url)
file_name = os.path.basename(img_url)
# 保存ディレクトリの作成
# 取得した火山名を使う
save_dir = os.path.join(dir_path,select_volcano)
# if not文で判断→フォルダがない→False→if notはTrue→フォルダを作る
if not os.path.isdir(save_dir):
os.makedirs(save_dir)
# 撮影の重複をチェック
check_file = os.path.join(save_dir,file_name)
# if notで判定する
# 条件が真ならif notは偽を返す
# 条件が偽ならif notは真を返す
# ファイルがない=撮影していない=if notがTrue=Trueの処理=キャプチャする
if not os.path.isfile(check_file):
with open(check_file,"wb") as f:
f.write(img.content)
# 次の時間に移動
forward.click()
time.sleep(1)
driver.quit()
print("終わりました")プログラムの機能は次のようになっています。
JMA火山監視カメラキャプチャ Ver.1.01(volcano_capture.py)
- 気象庁(JMA)が提供している火山監視カメラ画像について、
任意の火山画像をキャプチャ(保存)する - キャプチャする火山名はリストから選択する(番号を入力して指定)
- 画像を保存するフォルダ・ファイル名は自動で生成する
- 火山リストを更新(2022.7.27 カメラ追加のプレスリリースあり)
全体コードにはその役割ごとにブロック番号を付けています。
ブロック一覧とその役割
- プログラムで使用するモジュールの呼び出し
- ファイル保存や火山名の選択に使う変数やデータ
- 火山選択メニュー
- 選択された火山カメラをブラウザで読み込む
- キャプチャした画像の保存処理
今回はブロック4についての解説です。ちょっと長くなってしまいましたので前後半に分割しました。まずは前半です。後半部分はこちらからどうぞ。
ブロック4・火山カメラの読み込み(前半)
# ブロック4
chrome_driver = "(適当なディレクトリ)/chromedriver.exe"
chrome_service = service.Service(executable_path=chrome_driver)
driver = webdriver.Chrome(service=chrome_service)
wait = WebDriverWait(driver=driver, timeout=10)
driver.implicitly_wait(5)
driver.set_window_position(50,50)
driver.set_window_size(1400,1300)
# JMAの監視カメラ画像のページに直接アクセスする
driver.get("https://www.data.jma.go.jp/vois/data/tokyo/volcam/volcam.php")
# wait.until(EC.presence_of_all_elements_located)
# 選択された火山カメラを開く
volcam = driver.find_element(By.LINK_TEXT,select_volcano)
volcam.click()
# wait.until(EC.presence_of_all_elements_located)
# スライダを左端に移動
driver.find_element(By.CSS_SELECTOR,"img[src='./icon/player/oldest.png']").click()
# 早送りボタンを取得
forward = driver.find_element(By.CSS_SELECTOR,"img[src='./icon/player/next-frame.png']")Webブラウザをコントロールするための準備
このブロックを実行することで、気象庁の火山監視カメラのサイトにアクセスすることが可能となります。初回記事に動作デモの動画を掲載してありますが、プログラムを実行するとWebブラウザが起動することが確認できるかと思います。
つまり、ブロック4はWebブラウザをコントロールして気象庁のサイトにアクセスするためのコード群ということです。そして、そのための前段階としてSelenium(セレニウム)モジュールをブロック1で宣言しておいたのでした。
とは言え、実際にブラウザを立ち上げるには少し準備が必要です。初回記事ですでにブロック4の内容を先取りして少し解説をしていた所ですが、改めて各コードを見ていくことにしましょう。また、全編を通してWindows版のGoogle Chromeを使用していますので、それに沿った内容になります。
まずはdriverをダウンロード
chrome_driver = "(適当なディレクトリ)/chromedriver.exe"ブロック4・一行目のコードです。ブラウザをコントロールするためにはSeleniumだけではなく、それぞれのWebブラウザのdriverが必要になります(初回記事参照)。解釈としてはchrome_driverという変数にそのdriverのありかを教えて代入していることになります。
ですのでこのchromedriver.exeというファイルを入手する必要があります。

アクセスするとChromeDriverというシンプルなページが表示されると思います。All versions available in Downloadsという文言があり、ここからダウンロードを行います。Latest Beta ReleaseとLatest Stable Releaseの二つがありますが、基本的にはStable版を選択するのが良いでしょう。
また、このStable版のバージョン番号がお使いのChromeのそれとほぼ一致することを確認しておきます(本記事投稿時点では、113.0.5672まで一致していると思います。このバージョン番号が異なるとプログラムが動作しないことがあります)。
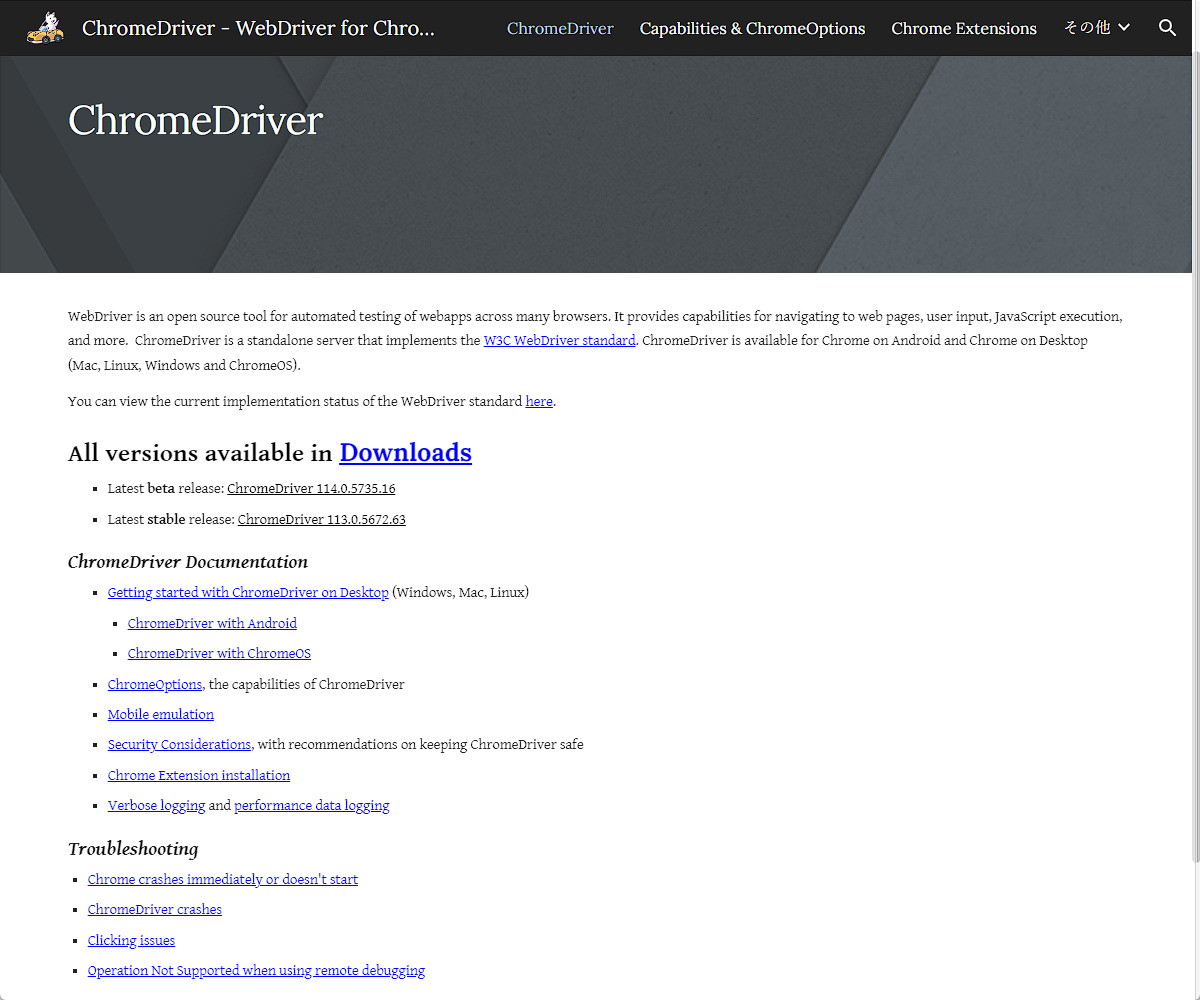
さらにいくつかのファイルが表示される画面になりますので、chromedriver_win32.zipをダウンロードし、展開します。そうするとchromedriver.exeが出てきます。
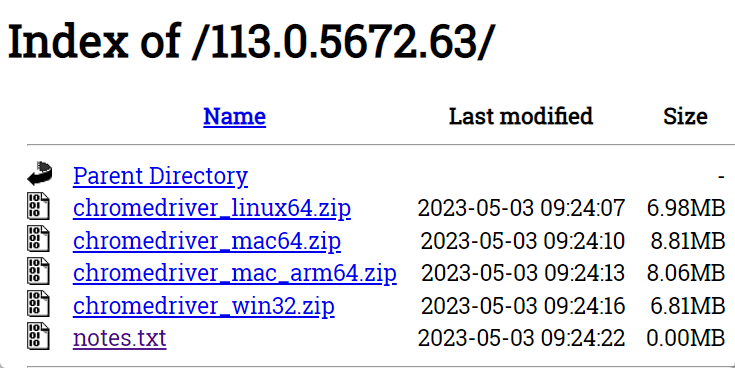
あとは適当なフォルダ(pythonプログラム関係のフォルダが無難でしょうか。私はanacondaを利用していますので、作成した仮想環境下のprogramsフォルダに入れています)にexeファイルを移動し、そのファイルパスを先のコードの(適当なディレクトリ)と置き換えます。これで一つ準備が完了です。
Serviceオブジェクトを作る
chrome_service = service.Service(executable_path=chrome_driver)driverファイルが準備できたので、この居場所をPythonに教えてやります。それが上のコードです。Serviceオブジェクト(インスタンスと言った方がより良いかも知れませんが)を生成しているのですが、ちょっとくわしく見ていきます。まず上のコードの右側についてです。
service.Service(executable_path=chrome_driver)serviceが二つ並んでおり、しかも二番目のそれは最初が大文字になっていますよね?serviceのServiceとは何だか訳が分からなくなりそうですが、一つずつ確認していくことでその意味が見えてきます。
まず最初のserviceについてです。こちらはブロック1においてインポートしたserviceモジュールのことです(ドライバのプロセスを管理(起動や終了)するために導入されたモジュールでしたね)。
from selenium.webdriver.chrome import serviceところで、Pythonにおけるモジュールというのは結局のところPythonのコードが書かれたpyファイルです。そしてそのファイルはどこにあるかというと、上のコードが示すそのままの階層に存在します。
お使いのPC環境やOSによって異なるとは思いますが、PythonをインストールしたフォルダのLibフォルダ下、site-packagesにseleniumフォルダがあると思います。それを見つけたらコードのドット部分をスラッシュに置き換えてディレクトリを探っていきましょう。chromeフォルダにたどり着くと思いますので、それを展開するといくつかのpyファイルが出てくるはずです。
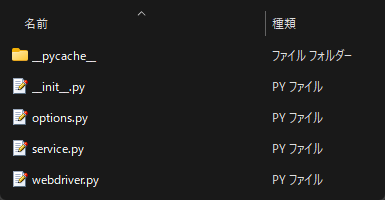
上の画像にもあります通り、先ほどインポートしたserviceという名のpyファイルがあるはずです。これがimport文によって読み込まれていることになります。その中身を確認してみますと
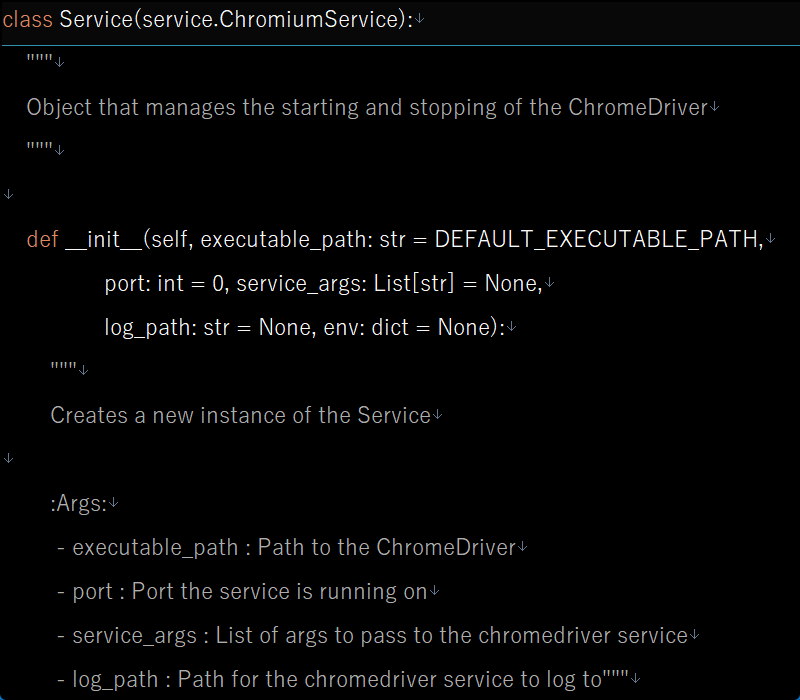
といったコードが出てきます。最初にclassと書かれていますよね?class文はクラス(Pythonのオブジェクト(インスタンス)の設計図となるもの)を定義する構文です。そしてclassの隣にはServiceとあります(最初のsが大文字です)。つまりservice.pyでServiceクラスを定義しています。
またServiceインスタンスが作られたときに、そのインスタンスが持つべき変数(アトリビュート)を決めることができます。それが先のdef文に続く__init__()の部分で、初期化メソッドと呼ばれます。
その括弧の中を追っていくと、self(インスタンス自身を示しており、必ずしもこの名前にする必要はないのですが慣例的に第一引数として使われているようです)に続いていくつかの引数が入っています。その中にexecutable_passという名前があり、ここにdriverのありかを渡してあげればServiceオブジェクトが機能するという仕組みです。
そしてオブジェクト(インスタンス)はクラスを次のように呼び出して作成します。
変数名 = クラス名(引数)最初のコードを再掲します。
chrome_service = service.Service(executable_path=chrome_driver)このように対比させればコードの意味が見えてきます。つまり右側のservice.Serviceはserviceモジュールで決められているServiceクラスを呼び出しており、その際Serviceクラスが持つべきexecutable_pathにchrome_driverを代入していることになります。それらをまとめてchrome_serviceという別の変数に納めているのがこのコードの機能です。
webdriverに渡してdriverを使えるようにする
ブラウザをコントロールするためのdriverをダウンロードし、それをServiceオブジェクトに格納する作業が終わりました。しかしブラウザを実際に動かすためにはwebdriverオブジェクトにdriverを渡さなければなりません。それを実行するのが次のコードです。
driver = webdriver.Chrome(service=chrome_service)この書式は先ほどオブジェクトを作成した時と同じような構文になっています。つまりwebdriverモジュールの中にあるChromeクラスを呼び出し、その引数であるserviceに今しがた作ったばかりのServiceオブジェクトであるchrome_serviceを渡し、それらをdriverという変数に入れるのがこの一行の意味です。
しかし、呼び出したのは良いのですが問題はこのChromeクラスが一体何者なのか?ということです。使いたいのはwebdriverオブジェクトであって、いきなりポッと出てきたChromeクラスではないはずです。ならばServiceの時と同じく関係するディレクトリを探ってみましょう。
まずwebdriverですが、ブロック1において次のように読み込んでいました。
from selenium import webdriverということは、seleniumフォルダ下にwebdriverフォルダがあるはずです。そこに__init__.pyというファイルが存在しており、これを開いてみますとfrom~import~という構文がぞろぞろと並んでいます。その中に
from .chrome.webdriver import WebDriver as Chrome という一文があります。どうやらまた別の所からWebDriverを呼び出しているようです。そして大事なのはその後に続くasの部分です。ここにChromeという単語がありますね。つまり本来WebDriverとして呼び出すべきものをChromeという名前で呼び出せるようにしている、というのがこの一文の意味です。
なので更にこの.chrome.webdriverの中身を追っていきます。最初にドットが付いていますから今いるwebdriverフォルダにさらにchromeフォルダがあり、さらにそこにwebdriver.pyというファイルがあると想像できます。果たして実際に追随していくとそのファイルがありました。中身は
# (ファイルの一部)
class WebDriver(ChromiumDriver):
def __init__(self, executable_path=DEFAULT_EXECUTABLE_PATH, port=DEFAULT_PORT,
options: Options = None, service_args=None,
desired_capabilities=None, service_log_path=DEFAULT_SERVICE_LOG_PATH,
chrome_options=None, service: Service = None, keep_alive=DEFAULT_KEEP_ALIVE):と何やらたくさんの変数が見受けられます。その全ては分かりませんが、WebDriverというクラスが定義されていることは分かります。そしてserviceという引数も定義されています。
つまり先のimport文で呼び出したWebDriverクラスがdriverを納めたかった対象であり、それをChromeという名前で扱うようにしているというのがwebdriver.Chromeの意味ということです。
driverは使用しているブラウザ毎に異なります。FirefoxあるいはEdgeなどを使われている方もおられると思います。そしてそれらをコントロールするにはwebdriverオブジェクトを作成してそこにdriverを渡す必要があります。ですのでasを使わなければおそらくは
driver = webdriver.WebDriver(service=chrome_service)も通るのではないかと思われます(試してはいませんが…)。webdriverフォルダには各ブラウザ名を冠したフォルダがあり、それぞれ中にwebdriver.pyファイルがあり、同様にWebDriverクラスが定義されていました。
ですので今回のように一つのブラウザだけを扱うのであれば今お示ししたコードでも良いのでしょうが、プログラムによっては複数のブラウザを扱うこともあるかも知れません。
そのような時にdriverの受け渡しを一つのWebDriverクラスでやり取りするといらぬ混乱を招くのだと思います。そこで__init__.pyファイルであらかじめ各ブラウザに対応するWebDriverに別名を与える運用にしているのだと思います。実際にこのpyファイルはフォルダをパッケージとして扱うためのものであり、パッケージ全体で扱う変数などを定義できる機能があるようです。
したがってChromeという名前はWebDriverの置き換えをしただけで実際にやっていることはwebdriverオブジェクトの生成であり、そこにdriverを渡しているということになります。
ともかくも、これでようやくブラウザをコントロールする土台が整ったことになります。
待機処理を設定する(暗示的な待機)
土台が出来ましたので早速読み込みを行いたいところですが、もう一手間をかけたいと思います。それが待機処理です。これについても初回記事で先取りしましたが、待機処理には明示的な待機と暗示的な待機の二つがあり、それを両方運用していると述べました。前者は解説済みですのでここでは暗示的な待機について見ていきます。それが次の一行です。
driver.implicitly_wait(5)
#implicity_wait(time_to_wait) time_to_waitは秒数括弧の数字の秒数分、driverで読み込むWebページの要素が見つかるまで処理を待つというものです。ブラウザを扱うdriverに関するメソッドなので、ここで設定した秒数分の待機処理が基本的にこれからの作業工程全てに適用されます。
ウインドウの位置とサイズを決める
# 開くウインドウの位置を決める
driver.set_window_position(50,50)
# set_window_position(x,y)
# xとyはモニタの左上を(x=0,y=0)とした時の座標(ピクセル)
# 開くウインドウのサイズを決める
driver.set_window_size(1400,1300)
# set_window_size(x,y)
# xとyはそれぞれ開くウインドウの横幅と縦幅(ピクセル)最後に立ち上げるブラウザウインドウの位置と大きさを設定します。ここはお使いのブラウザに合わせて調整すれば良いでしょう。またウインドウを最大化して運用したい場合はset_window_size()ではなく
# 開くウインドウのサイズを最大にする
driver.maximize_window()に置き換えることで可能になります。
ブラウザの立ち上げはたった一行のコードで
大変お待たせしました。いよいよブラウザのコントロールに入ります。ここまで大層な準備を行ってきましたからさぞかし大仰なコードの羅列が登場するのかと思いきや、入力するコードは次のたった一行のみになります。実行すると先のコードで設定した位置とサイズでウインドウが立ち上がるはずです。
# JMAの監視カメラ画像のページに直接アクセスする
driver.get("https://www.data.jma.go.jp/vois/data/tokyo/volcam/volcam.php")
# get(url)
# urlにアクセスしたいサイトのURLを入力挙動を確認するだけでしたら、ブロック1+ブロック4のget()部分までで十分に確認できます。ところで立ち上げたウインドウを確認してみると次の文言が出ていることに気が付かれるかと思います。

Pythonとブラウザの間でwebdriverが機能していることがこの一文からも読み取れます。
まとめです
Pythonを用いたプログラミングについて、火山カメラ画像キャプチャのブロック4・前半部分についてその仕組みを見てきました。実際に立ち上げたブラウザをどのようにコントロールしていくのか?それが後半部分で考えていくテーマです。
ぜひWebブラウザでJMAの該当ページを開きながらコードとの関連性を突き合わせてみて下さい。後半に続きます。
